
Social Media Analyse en Text mining met R: De Ziggo en Ajax case
Reacties van Twitteraars op de sponsordeal van Ziggo en Ajax
Op verschillende manieren kan social media een rijke bron aan nuttige informatie voor bedrijven zijn, afhankelijk van de manier waarop het gebruikt wordt. Door het analyseren van een grote hoeveelheid tweets kan achterhaald worden wat de mening is van de grote meute, iets dat voor bepaalde bedrijven belangrijke informatie is. Zo kan uitgezocht worden hoe twitteraars over bepaalde bedrijven of over bepaalde onderwerpen denken. Tegenwoordig zijn de mogelijkheden zo goed als eindeloos met de tools die tegenwoordig beschikbaar zijn. In deze post gebruik ik de open source statistische tool R om tweets te analyseren. Ik analyseer de tweets die over de sponsordeal tussen Ziggo en Ajax gaan. Alhoewel dit destijds een vrij bekend topic was en er geen uitgebreide analyse van twitter nodig is om er achter te komen hoe mensen hierover denken (het nieuws stond er vol van), kan er met dit onderwerp juist aangetoond worden dat de uitkomsten van de analyse kloppen. Let’s go!
Deze post bestaat uit de volgende onderdelen:
- Frequente termen op Twitter uitzoeken;
- Samenhang en correlaties tussen termen in tweets vinden;
- Samenvatting van onderwerpen uit de tweets weergeven door clustering.
Zelf Twitter Data Analyseren?
Als je op zoek bent naar een instructie om zelf Twitter data te ontsluiten en analyseren, kun je de pagina Hands-on: Tweets importeren, analyseren en Text Mining in R bezoeken. Ben je op zoek naar een applicatie om eenvoudig Tweets meet te analyseren zonder hiervoor te hoeven programmeren, kun je de applicatie TweetExplorer gebruiken. Voor een instructie van deze applicatie, ga kun je de pagina Twitter timelines: Wordclouds maken, onderzoek doen en tweets downloaden bezoeken.
Frequente termen opzoeken
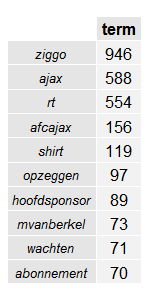
Voor deze case zijn er 1000 tweets geïmporteerd om 15:00 uur op 7 november 2014. Uiteraard tweets die de term “Ziggo“ bevatten. De onderstaande afbeelding laat zien wat de top 10 is van frequente termen uit deze set aan tweets en hoe vaak deze tweets voorkomen.
Een wordcloud is ook een manier om de frequentie van de tweets weer te geven:
 Zoals te verwachten, komt de term “Ziggo” het meeste voor. Uit de overige frequente termen kun je al een beetje de algemene gedachte van de tweets zien. Te zien is dat Ajax ook vaak voorkomt in “tweets” waar de term “ziggo” in voor komt, blijkbaar hebben deze termen dus iets met elkaar te maken. Echter is het een vrij zwakke vorm van social media analyse als op basis van deze analyse uitspraken worden gedaan. Toevallig weten we over dit onderwerp dat het wel klopt, maar toch zijn we op zoek naar iets meer bewijs dat deze termen uit de tweets daadwerkelijk met elkaar samenhangen, correlaties!
Zoals te verwachten, komt de term “Ziggo” het meeste voor. Uit de overige frequente termen kun je al een beetje de algemene gedachte van de tweets zien. Te zien is dat Ajax ook vaak voorkomt in “tweets” waar de term “ziggo” in voor komt, blijkbaar hebben deze termen dus iets met elkaar te maken. Echter is het een vrij zwakke vorm van social media analyse als op basis van deze analyse uitspraken worden gedaan. Toevallig weten we over dit onderwerp dat het wel klopt, maar toch zijn we op zoek naar iets meer bewijs dat deze termen uit de tweets daadwerkelijk met elkaar samenhangen, correlaties!
Samenhang en correlaties tussen termen in de tweets vinden
In de statistiek wordt er met correlaties de samenhang tussen twee verschillende variabelen aangegeven. De waarde van een correlatie varieert van o tot 1. Bijvoorbeeld de correlatie tussen een datum waarbij 9 maanden geleden de stroom is uitgevallen en het geboortecijfer heeft een correlatie van 0.6 (even een random getal). Dit betekend dat deze twee gegevens vrij sterke samenhang hebben. Voor de analyse op twitter worden hier correlaties tussen termen gemaakt. Het algoritme dat met R wordt toegepast berekend in hoeverre termen in dezelfde tweet voorkomen en hoe dicht de termen naast elkaar staan in een tweet. Des te meer dit voorkomt en des te dichter ze bij elkaar staan, des te hoger te correlatie (met uiteraard 1 als maximum maar dit komt nevernooit voor, ook niet in de statistiek, in ieder geval zeer zelden). Er wordt op termen gezocht die de hoogste correlaties hebben met de term “ziggo“.
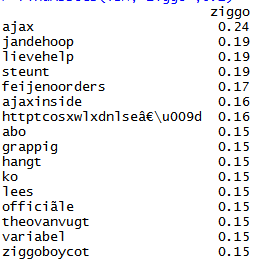
Oke, nu hebben we meer bewijs dat de termen “Ziggo” en “Ajax” samenhangen, 0.24 is een vrij hoge correlatie als er gezocht is naar tweets waarin de term “ziggo” voorkomt, de term “ajax” is erg geassocieerd met deze term. Op basis van de correlaties kunnen we het onderstaande dendogram maken.
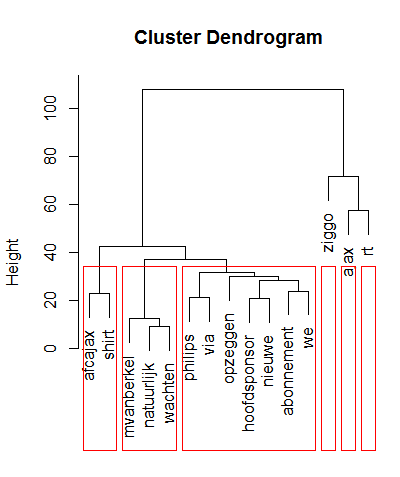
Op de y-as laat het dendogram zien hoe hoog of hoe belangrijk de termen zijn in de collectie tweets. Hierin is te zien dat “ziggo”, “ajax” en “rt” (retweet) de belangrijkste topics waren. Verder is in het dendogram te zien welke andere termen een samenhang hebben, voor de duidelijkheid is dit aangegeven met de rode vakjes. Nu we de correlaties hebben gevonden hebben we wel enigszins meer inzicht en bewijs gezien over de samenhang van de termen. Toch willen we iets meer inzicht. We willen in algemene zinnen te zien krijgen wat deze collectie aan tweets ons zegt.
Samenvatting van onderwerpen weergeven door clustering
Als we clusters hebben van termen kunnen we beter achterhalen wat de algemene gedachten van de tweets zijn, hiermee worden zinnen gevormd die we kunnen interpreteren als bepaalde informatie –> het uiteindelijke doel van deze social media analyse. Hiervoor kunnen twee methodes gebruikt worden; k-mean clustering en het LDA-algoritme. K-mean clustering van termen, een algemene toepassing voor data mining en nu dus toegepast voor text mining. Het algoritme is een vrij bekend algoritme in de data mining wereld en kan vrij eenvoudig gebruikt worden in R. Het LDA-algoritme geeft aan wat de voornaamste onderwerpen in een bepaalde text dataset zijn, het resultaat is vergelijkbaar als met k-mean clustering. Hieronder wordt de output weergegeven van de k-mean clustering en het LDA-algoritme.

K-mean clustering resultaat
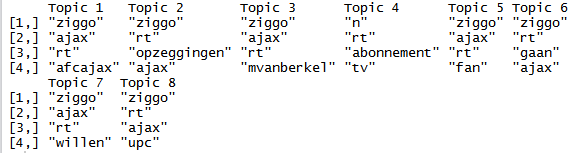
LDA-algoritme resultaat
Beide resultaten geven aan dat er met de termen “ziggo”, “ajax”, “opzeggen”, “abonnement”, “hoofdsponsor” etc. een zin gemaakt moet worden. Hieruit kan uit een grote hoeveelheid tweets (1000) met een paar handelingen door text mining met R waardevolle informatie gevonden kan worden.
Dus wat kunnen bedrijven hier mee?
Zoals ik in het begin al aangaf, deze situatie met Ziggo en Ajax is bekend geworden op het nieuws waardoor deze analyse eigenlijk niet nodig is. Dit voorbeeld heeft echter aangetoond dat de resultaten van de analyse kloppen met de nieuwsberichten. Voor bedrijven waarbij het gedrag van hun klanten niet op het nieuws komt, is het een waardevolle manier van marktonderzoek. In plaats van veel tijd besteden aan vragenlijsten (waar mensen steeds minder zin in hebben om deze in te vullen) kan op deze manier de mening gepeild en eventueel andere informatie over de klant gevonden worden. Handmatig analyseren wat er wordt verteld op Twitter kost vrij veel tijd en is vrij onmogelijk met zoveel tweets, om nog niet te spreken over de benodigde berekeningen. Sentiment analyses zijn er ook, maar dan weet je niet WAT de klant zegt. Met deze manier van social media analyse kunnen bedrijven achterhalen uit een grote hoeveelheid recente tweets (of uit een ander tijdstip) hoe klanten over een bepaald onderwerp denken of over hun bedrijf denken. De algemene zinnen die gemaakt kunnen worden uit de associaties en resultaten van de k-mean clustering en LDA-algoritme zijn tenslotte gebaseerd op feiten, and facts don’t lie.

Plaats een reactie