
Algoritmes volledig vertrouwen?
Een wereld vol algoritmes
Algoritmes, of eigenlijk voorspellingsmodellen die worden ontwikkeld met behulp van deze algoritmes, spelen op dit moment al een belangrijke rol in ons dagelijkse leven. (Laten we een model voor het gemak in dit artikel even algoritme noemen. Dit maakt het even makkelijker, is meer trendy en is goed voor mijn SEO). En ik kan niet anders zeggen dat dit alleen maar gaat toenemen. Natuurlijk zijn ze bedoeld om ons het leven makkelijker te maken. Denk bijvoorbeeld aan je Daily Mix of Spotify of Google die jouw zoekopdracht al keurig netjes voor je afmaakt voordat je het zelfs al in je hoofd hebt bedacht.
“Waarom moet ik een voorspelling van een algoritme vertrouwen?”
Zijn voorspellingsmodellen getraind met algoritmes een black box?
Het korte antwoord is nee. Ontwikkelaars van algoritmes weten heel goed hoe een algoritme is opgebouwd en naar welke eigenschappen er wordt gekeken. Dit is overigens voor Machine Learning algoritmes, zoals algoritmes/modellen die gebruikt worden bij Fraude Detectie, makkelijker dan Deep Learning modellen die bijvoorbeeld herkend worden bij het herkennen van plaatjes of objecten in plaatjes.
Voorspellingen van een model uitleggen
Echter “vertellen” algoritmes niet hoe ze aan een individuele voorspelling zijn gekomen. Even simpeler gezegd: “Een algoritme geeft geen onderbouwing voor zijn conclusie dat jij in een situatie als fraudeur wordt aangemerkt”. Een mens kun je keurig netjes een onderbouwing geven voor zijn oordeel, maar een algoritme niet. En dat is niet een heel fijn gevoel als je weet dat we er toch aan moeten geloven dat voorspellingsmodellen gebouwd met algoritmes een steeds belangrijkere rol in ons leven gaan spelen.
H2O LIME: Een nieuw speeltje voor Data Scientists en Machine Learning Engineers
H2O.ai is een grote speler op het gebied van het toepassen van Machine Learning algoritmes en tools voor het bouwen van voorspellingsmodellen. Tijdens de Open Data Science Conferentie (ODSC) in 2018 in Londen heb ik een ontwikkelaar van H2O zien spreken over Automated Machine learning en LIME. En vooral het LIME gedeelte vond ik interessant omdat deze techniek omgaat met de vraag:”Waarom moet ik een individuele voorspelling van een algoritme vertrouwen?”.
LIME staat voor Local Interpretable Model-agnostic Explanations. Simpel gezegd wat H2O LIME doet, is simpele lokale modellen trainen voor verzamelingen aan datapunten die zich in de dataset bevinden. LIME is in staat om deze lokale modellen uit te leggen.
In dit artikel H2O LIME uitgebreid uitgelegd: https://uc-r.github.io/lime
Code
Graag wil ik in dit artikel daar iets kort over demonstreren. Ik neem de klassieke German Dataset als voorbeeld. Dit is een dataset uit 1994 waarin data over aanvragen voor leningen bij een bank zijn verzameld en is gekeken of leningen aan het einde van de looptijd zijn terugbetaald of niet. Daarbij is goed bijgehouden wat de eigenschappen zijn van de personen die een lening hebben aangevraagd. Op deze manier zou je verbanden kunnen vinden tussen eigenschappen van aanvragers van leningen en de kans dat een lening uiteindelijk wordt terugbetaald of niet.
Voor de ontwikkelaars: Open uw laptops en editors , want ik voeg de code toe in dit artikel. Het is gemaakt in R. Ik weet het ik ben de laatste tijd meer een Python man en ook vreemd omdat ik twee weken geleden een boek over Python heb gepubliceerd, maar ik ben nog steeds een groot van van R.
Een voorspellingsmodel trainen
Laten we eerste de nodige packages openen en de data importeren:
library(h2o) # for training the prediction models
library(dplyr) # for data wrangling
library(lime) # for explaining predictions
library(readr) # for importing the dataset
library(caret) # for creating data partitions
Vervolgens importeren we de bekende German Dataset
german_data <- read_table2("data/german.data.txt", col_names = FALSE)
Omdat de dataset nog niet de juiste namen heeft, voegen wij deze toe. Op basis van de bijlage (het Word-document) die op de pagina van de German dataset, kan ik de namen eenvoudig volgens de dplyr syntax aanpassen.
german_data <- german_data %>%
rename(checking_account = X1) %>%
rename(duration_months = X2) %>%
rename(credit_history = X3) %>%
rename(purpose = X4) %>%
rename(credit_amount = X5) %>%
rename(savings = X6) %>%
rename(present_employment_since = X7) %>%
rename(installment_rate = X8) %>%
rename(personal_status_sex = X9) %>%
rename(other_deptors = X10) %>%
rename(present_residence = X11) %>%
rename(property = X12) %>%
rename(age_years = X13) %>%
rename(other_installment_plans = X14) %>%
rename(housing = X15) %>%
rename(existing_credits = X16) %>%
rename(job = X17) %>%
rename(people_liable_maintenance = X18) %>%
rename(telephone = X19) %>%
rename(foreign_worker = X20) %>%
rename(response = X21)
Ook de waarden van de variabelen moeten worden aangepast. Deze zijn in de originele dataset gecodeerd in een formaat die met behulp van de bijlage gelezen kan worden. Echter is het dan niet leesbaar voor de uitleg van de voorspellingen die we straks gaan genereren. Ook hier gebruik ik de dplyr syntax voor:
german_data <- german_data %>%
# checking_account
mutate(checking_account=replace(checking_account, checking_account=='A11', '... < 0 euro')) %>%
mutate(checking_account=replace(checking_account, checking_account=='A12', '0 <= ... < 102 euro')) %>%
mutate(checking_account=replace(checking_account, checking_account=='A13', '>= 102 euro')) %>%
mutate(checking_account=replace(checking_account, checking_account=='A14', 'No checking account')) %>%
# duration_months --> Is an integer value so nothing to change for this feature
mutate(credit_history=replace(credit_history, credit_history=='A30', 'no credits taken/ all credits paid back duly')) %>%
mutate(credit_history=replace(credit_history, credit_history=='A31', 'all credits at this bank paid back duly')) %>%
mutate(credit_history=replace(credit_history, credit_history=='A32', 'existing credits paid back duly till now')) %>%
mutate(credit_history=replace(credit_history, credit_history=='A33', 'delay in paying off in the past')) %>%
mutate(credit_history=replace(credit_history, credit_history=='A34', 'critical account/other credits existing (not at this bank)')) %>%
# purpose
mutate(purpose=replace(purpose, purpose=='A40', 'car (new)')) %>%
mutate(purpose=replace(purpose, purpose=='A41', 'car (used)')) %>%
mutate(purpose=replace(purpose, purpose=='A42', 'furniture/equipment')) %>%
mutate(purpose=replace(purpose, purpose=='A43', 'radio/television')) %>%
mutate(purpose=replace(purpose, purpose=='A44', 'domestic appliances')) %>%
mutate(purpose=replace(purpose, purpose=='A45', 'repairs')) %>%
mutate(purpose=replace(purpose, purpose=='A46', 'education')) %>%
mutate(purpose=replace(purpose, purpose=='A47', '(vacation - does not exist?)')) %>%
mutate(purpose=replace(purpose, purpose=='A48', 'retraining')) %>%
mutate(purpose=replace(purpose, purpose=='A49', 'business')) %>%
mutate(purpose=replace(purpose, purpose=='A410', 'others')) %>%
# credit_acount --> Is an integer value so nothing to change for this feature
mutate(savings=replace(savings, savings=='A61', '... < 51 euro')) %>%
mutate(savings=replace(savings, savings=='A62', '51 <= ... < 255 euro')) %>%
mutate(savings=replace(savings, savings=='A63', '255 euro <= ... < 511 euro')) %>%
mutate(savings=replace(savings, savings=='A64', '.. >= 511 euro')) %>%
mutate(savings=replace(savings, savings=='A65', 'unknown/ no savings account')) %>%
# present employment since
mutate(present_employment_since=replace(present_employment_since, present_employment_since=='A71', 'unemployed')) %>%
mutate(present_employment_since=replace(present_employment_since, present_employment_since=='A72', '... < 1 year')) %>%
mutate(present_employment_since=replace(present_employment_since, present_employment_since=='A73', '1 <= ... < 4 years')) %>%
mutate(present_employment_since=replace(present_employment_since, present_employment_since=='A74', '4 <= ... < 7 years')) %>%
mutate(present_employment_since=replace(present_employment_since, present_employment_since=='A75', '.. >= 7 years')) %>%
# Installment rate of disposable income--> Is an integer value so nothing to change for this feature
mutate(personal_status_sex=replace(personal_status_sex, personal_status_sex=='A91', 'male : divorced/separated')) %>%
mutate(personal_status_sex=replace(personal_status_sex, personal_status_sex=='A92', 'female : divorced/separated/married')) %>%
mutate(personal_status_sex=replace(personal_status_sex, personal_status_sex=='A93', 'male : single')) %>%
mutate(personal_status_sex=replace(personal_status_sex, personal_status_sex=='A94', 'male : married/widowed')) %>%
mutate(personal_status_sex=replace(personal_status_sex, personal_status_sex=='A95', 'female : single')) %>%
# other debtors/guarantors
mutate(other_deptors=replace(other_deptors, other_deptors=='A101', 'none')) %>%
mutate(other_deptors=replace(other_deptors, other_deptors=='A102', 'co-applicant')) %>%
mutate(other_deptors=replace(other_deptors, other_deptors=='A103', 'guarantor')) %>%
# present residence since --> Is an integer value so nothing to change for this feature
mutate(property=replace(property, property=='A121', 'real estate')) %>%
mutate(property=replace(property, property=='A122', '(if not real estate) building society savings agreement/ life insurance')) %>%
mutate(property=replace(property, property=='A123', '(if not optin 1 or 2) car or other, not in attribute')) %>%
mutate(property=replace(property, property=='A124', 'unknown / no property')) %>%
# age in years --> Is an integer value so nothing to change for this feature
mutate(other_installment_plans=replace(other_installment_plans, other_installment_plans=='A141', 'bank')) %>%
mutate(other_installment_plans=replace(other_installment_plans, other_installment_plans=='A142', 'stores')) %>%
mutate(other_installment_plans=replace(other_installment_plans, other_installment_plans=='A143', 'none')) %>%
# housing
mutate(housing=replace(housing, housing=='A151', 'rent')) %>%
mutate(housing=replace(housing, housing=='A152', 'own')) %>%
mutate(housing=replace(housing, housing=='A153', 'for free')) %>%
# existing_credits --> Is an integer value so nothing to change for this feature
mutate(job=replace(job, job=='A171', 'unemployed/ unskilled - non-resident')) %>%
mutate(job=replace(job, job=='A172', 'unskilled - resident')) %>%
mutate(job=replace(job, job=='A173', 'skilled employee / official')) %>%
mutate(job=replace(job, job=='A174', 'management/ self-employed/highly qualified employee/ officer')) %>%
# people_liable_maintenance --> Is an integer value so nothing to change for this feature
mutate(telephone=replace(telephone, telephone=='A191', 'none')) %>%
mutate(telephone=replace(telephone, telephone=='A192', 'yes, registered under the customers name')) %>%
# foreign worker
mutate(foreign_worker=replace(foreign_worker, foreign_worker=='A201', 'yes')) %>%
mutate(foreign_worker=replace(foreign_worker, foreign_worker=='A202', 'no')) %>%
# paid back
mutate(response = response - 1) %>% mutate(response = as.factor(response)) # modify so we get values between 0 and 1
Vervolgens geven we aan welke variabele wij in dit geval willen voorspellen en met welke variabelen we dit gaan doen. De variabele die we in dit geval willen voorspellen is response. Deze variabele geeft aan of een lening uiteindelijk is terugbetaald of niet.
# get the character columns
charCols <- german_data %>%
sapply(., class) %in%'character' %>% # get logical values if given column is a character
german_data[,.] %>% # get the actual columns
names() # create the final vector that contains the names of the character columns
# change the character columns to factors
german_data <- german_data %>%
mutate_at(charCols, as.factor) # change character columns to the 'factor' data type
target <- "response" # specify the target, what will be predicted
features <- setdiff(names(german_data), target) # specify the features to use for the prediction
print(features)
## [1] "checking_account" "duration_months"
## [3] "credit_history" "purpose"
## [5] "credit_amount" "savings"
## [7] "present_employment_since" "installment_rate"
## [9] "personal_status_sex" "other_deptors"
## [11] "present_residence" "property"
## [13] "age_years" "other_installment_plans"
## [15] "housing" "existing_credits"
## [17] "job" "people_liable_maintenance"
## [19] "telephone" "foreign_worker"
Vervolgens verdelen we de dataset in een train-, validatie- en testset.
set.seed(4650)
train_index <- createDataPartition(german_data$response,
p = .75,
list = FALSE,
times = 1)
train <- german_data[ train_index,]
tmp <- german_data[-train_index,]
tmp_index <-createDataPartition(tmp$response,
p = 0.5,
list = FALSE,
times = 1)
test <- tmp[tmp_index,]
val <- tmp[-tmp_index,]
# remove useless variables
rm(tmp, tmp_index, train_index)
H2O AutoML gebruiken on
We gaan het uitproberen van verschillende voorspellingsmodellen en configuraties (hyperparameters) van voorspellingsmodellen automatiseren.
Hiervoor is het nodig om zogenaamde H2O DataFrames te maken van de train, validatie, en testset.
h2o.init()
h_train <- as.h2o(train)
h_test <- as.h2o(test)
h_val <- as.h2o(val)
We gaan nu de Automated Machine Learning (AutoML) van H2O starten. We geven aan dat de AutoML een kwartier de tijd heeft om verschillende voorspellingen te trainen. Uiteindelijk kiezen wij van deze modellen het beste model uit.
model_automl = h2o.automl(x = features, # specify the features (x) of the model
y = target, # specify the target (y) of the model
training_frame = h_train, # specify the training set
validation_frame = h_val, # specify the validation set
#nfolds = 5, # Kfolds
max_runtime_secs = 900,
# Max time
#max_models = 100, # or Max no. of models
stopping_metric = "AUC", # Metric to optimize
project_name = "automl_credit", # useful if you want to add more models in future
exclude_algos = c("DeepLearning", "XGBoost"), # which algorithms not to try
seed = 12345) # to make the sample reproducable
Let op dat ik met exclude_algos aangeef dat ik in dit geval geen XGBoost of DeepLearning techniek wil toepassen.
Als de AutoML van H2O klaar is, kunnen we aan de hand van een scorebord (het leaderboard) een lijstje zien van de beste modellen die in het afgelopen kwartier door de AutoML zijn getraind.
model_automl@leaderboard
## model_id auc logloss
## 1 GLM_grid_1_AutoML_20190403_122551_model_1 0.7957884 0.4879622
## 2 GLM_grid_1_AutoML_20190403_140332_model_1 0.7957884 0.4879622
## 3 GLM_grid_1_AutoML_20190403_142415_model_1 0.7957884 0.4879622
## 4 GLM_grid_1_AutoML_20190403_122831_model_1 0.7957884 0.4879622
## 5 GLM_grid_1_AutoML_20190403_142447_model_1 0.7957884 0.4879622
## 6 GLM_grid_1_AutoML_20190403_121639_model_1 0.7902498 0.4887635
## mean_per_class_error rmse mse
## 1 0.2596825 0.4000846 0.1600677
## 2 0.2596825 0.4000846 0.1600677
## 3 0.2596825 0.4000846 0.1600677
## 4 0.2596825 0.4000846 0.1600677
## 5 0.2596825 0.4000846 0.1600677
## 6 0.2748397 0.4011886 0.1609523
##
## [116 rows x 6 columns]
Laten we in dit geval simpelweg voor het best getrainde model kiezen. We genereren gelijk een aantal voorspellingen, gewoon om even een kijkje te nemen.
predmodel <- model_automl@leader
pred_test <- h2o.predict(predmodel, h_test)
pred_test
## predict p0 p1
## 1 0 0.8965881 0.1034119
## 2 1 0.3520544 0.6479456
## 3 1 0.4584328 0.5415672
## 4 0 0.8975724 0.1024276
## 5 1 0.5212968 0.4787032
## 6 0 0.8910629 0.1089371
##
## [126 rows x 3 columns]
Laten we ook 1 individuele voorspelling bekijken.
predictions_df <- as.data.frame(pred_test)
final_prediction <- paste0(as.character(round(predictions_df$p1[1], 3) * 100), " %")
final_prediction
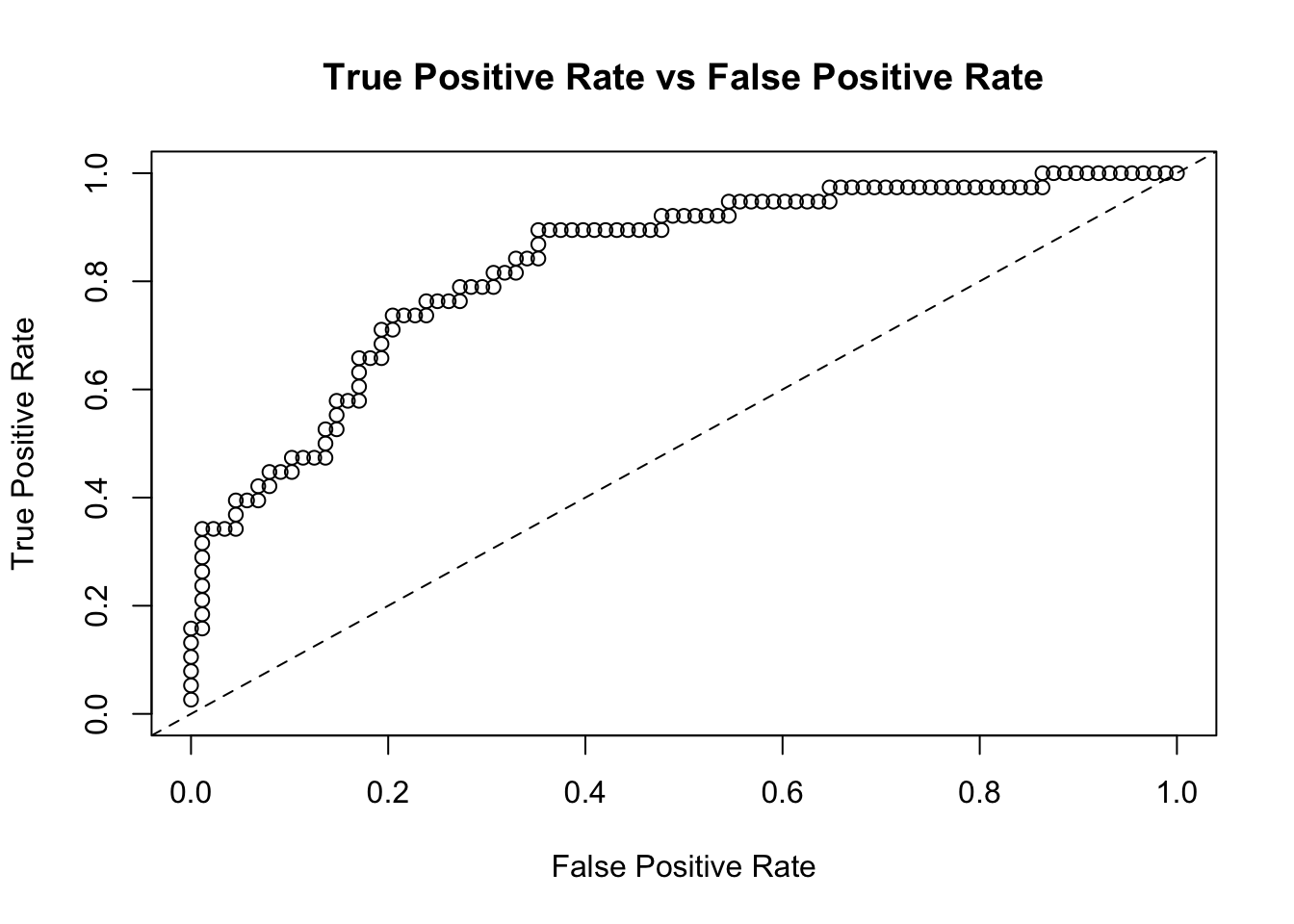
## [1] "10.3 %"Laten we voor dit classificatiemodel die we getraind hebben ook een ROC curve zien.
model_perf = h2o.performance(model=predmodel, h_test)
plot(model_perf, type = "roc")
h2o.table(pred_test$predict, h_test$paid_back)
Een confusion matrix
## predict Count
## 1 0 88
## 2 1 38
##
## [2 rows x 2 columns]
En natuurlijk kunnen we het model opslaan.
# Save model to disk
h2o.saveModel(object = predmodel,
path = "./models/",
force = TRUE)
h2o.saveMojo(object = predmodel,
path = "./models/")
Voorspellingen door een voorspellingsmodel uitleggen met H2O Lime
Nu we ons voorspellingsmodel hebben getraind, kunnen we H2O LIME gebruiken om de voorspellingen uit te leggen. Hier wordt een voorspelling of een persoon een lening uiteindelijk gaat terugbetalen onderbouwd.
We creëren de explainer
explainer <- lime::lime(x = as.data.frame(h_train[, features]),
model = predmodel)
We nemen twee situaties uit de test-set. In dit geval dus twee aanvragen van leningen.
sample <- as.data.frame(h_test[c(2,3), features])
row.names(sample) <- c("--- Example 1 ---", "--- Example 2 ---")
sample[is.na(sample)] <- 0
print(t(sample))
## --- Example 1 ---
## checking_account "0 <= ... < 102 euro"
## duration_months "12"
## credit_history "existing credits paid back duly till now"
## purpose "car (new)"
## credit_amount "1295"
## savings "... < 51 euro"
## present_employment_since "... < 1 year"
## installment_rate "3"
## personal_status_sex "female : divorced/separated/married"
## other_deptors "none"
## present_residence "1"
## property "(if not optin 1 or 2) car or other, not in attribute"
## age_years "25"
## other_installment_plans "none"
## housing "rent"
## existing_credits "1"
## job "skilled employee / official"
## people_liable_maintenance "1"
## telephone "none"
## foreign_worker "yes"
## --- Example 2 ---
## checking_account "... < 0 euro"
## duration_months "24"
## credit_history "existing credits paid back duly till now"
## purpose "radio/television"
## credit_amount "1282"
## savings "51 <= ... < 255 euro"
## present_employment_since "1 <= ... < 4 years"
## installment_rate "4"
## personal_status_sex "female : divorced/separated/married"
## other_deptors "none"
## present_residence "2"
## property "(if not optin 1 or 2) car or other, not in attribute"
## age_years "32"
## other_installment_plans "none"
## housing "own"
## existing_credits "1"
## job "unskilled - resident"
## people_liable_maintenance "1"
## telephone "none"
## foreign_worker "yes"Laten we de explanations samenstellen en bekijken.
# Create explanations
set.seed(12345)
explanations <- lime::explain(x = sample,
explainer = explainer,
feature_select = "highest_weights",
labels = "p0",
n_features = 20) # Look top n features
lime::plot_features(explanations, ncol = 2)
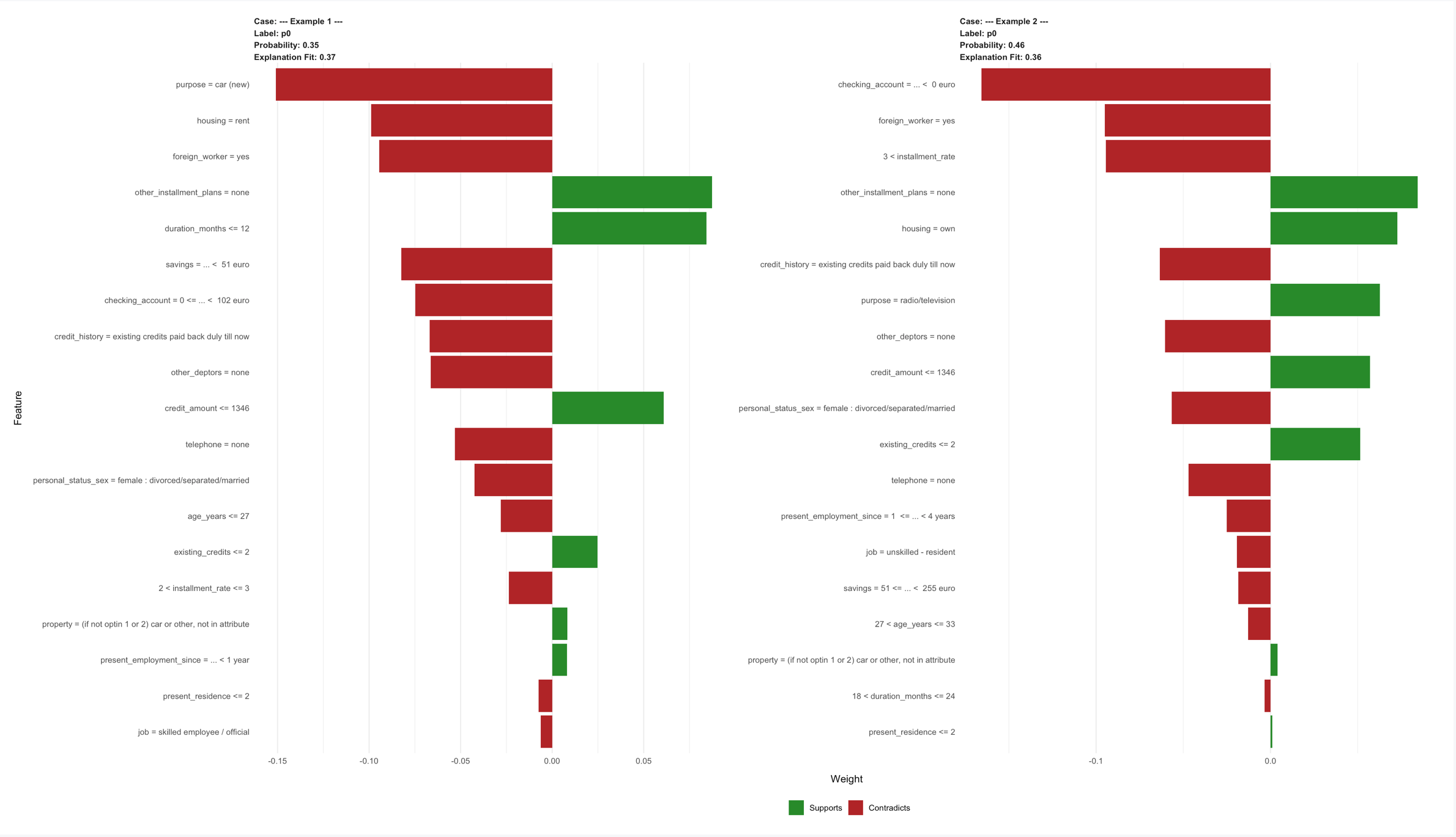
Als je de bovenstaande afbeelding vergroot, kun je voor deze twee situaties de onderbouwingen zien. De bovenste twee voorspellingen geven achter Probabilityaan dat de kansen respectievelijk 35% en 46% zijn dat de personen de lening kunnen terugbetalen. Fit geeft in dit geval aan hoe betrouwbaar deze explanations zijn.
In het eerste voorbeeld zie je bijvoorbeeld dat het feit dat de reden om geld te lenen een nieuwe auto is (purpose=car(new) een drijfveer is om het kredietrisico te vergroten. Dit geldt ook voor het feit dat de aanvrager een huurhuis heeft (housing=rent). De drijfveren die de kans op het niet terugbetalen van de lening worden in het groen aangegeven. Dit zie je bijvoobeeld aan other installment plans = None, dit geeft namelijk aan de de aanvrager op dit moment geen andere afbetalingen heeft openstaan.
In het eerste voorbeeld zie je bijvoorbeeld dat het feit dat de reden om geld te lenen een nieuwe auto is (purpose=car(new) een drijfveer is om het kredietrisico te vergroten. Dit geldt ook voor het feit dat de aanvrager een huurhuis heeft (housing=rent). De drijfveren die de kans op het niet terugbetalen van de lening worden in het groen aangegeven. Dit zie je bijvoobeeld aan other installment plans = None, dit geeft namelijk aan de de aanvrager op dit moment geen andere afbetalingen heeft openstaan.
In het eerste voorbeeld zie je bijvoorbeeld dat het feit dat de reden om geld te lenen een nieuwe auto is (purpose=car(new) een drijfveer is om het kredietrisico te vergroten. Dit geldt ook voor het feit dat de aanvrager een huurhuis heeft (housing=rent). De drijfveren die de kans op het niet terugbetalen van de lening worden in het groen aangegeven. Dit zie je bijvoobeeld aan other installment plans = None, dit geeft namelijk aan de de aanvrager op dit moment geen andere afbetalingen heeft openstaan.
De explanations moeten trouwens niet verward worden met de Variable Importance Plot. Het kan zijn dat hier andere variabele een belangrijke rol spelen voor de voorspellingen. Let op: De explanations van LIME geven de belangrijke aan voor de kleine lokale modellen en de Variable Importance Plot geeft het aan voor het echte (grote/algemene) model.
h2o.varimp_plot(predmodel)
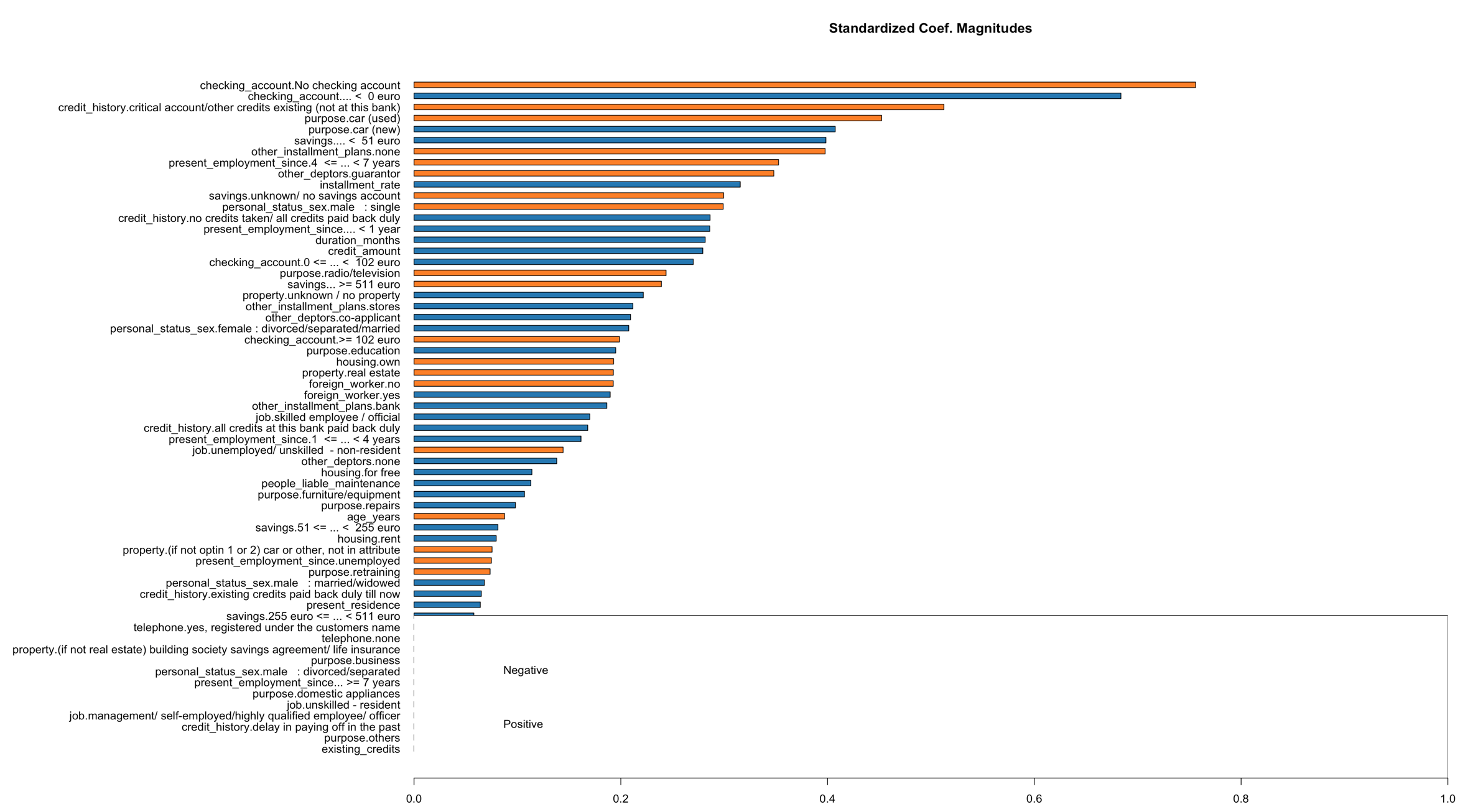
Het is dus leuk om de onderbouwing van voorspellingen weer te geven. H2O maakt dit mogelijk door lokale modellen te trainen met H2O LIME. Speel er eens wat mee en gebruik het bijvoorbeeld bij eerdere classificatiemodellen die je getraind hebt. Eindgebruikers van voorspellingsmodellen vinden het waardevol om een voorspelling te onderbouwen, zeker als het om belangrijke zaken gaat.

3 Comments
Gaaf artikel! Ik vind Machine Learning en statistische modellen fascinerend maar nog wel lastig te begrijpen. Van jouw artikel word ik enthousiast om er verder in te duiken. Dankjewel!
Een kleine tip:
Bij het aanpassen van de waarden van de variabelen heeft dplyr nog een handigheidje die ik laatst ontdekt heb: case_when. Minder typen, minder kans op fouten en meer leesbaarheid:
german_data %
mutate(
checking_account = case_when(
checking_account == ‘A11’ ~ ‘… < 0 euro',
checking_account == 'A12' ~ '0 <= … = 102 euro’,
checking_account == ‘A14’ ~ ‘No checking account’
),
credit_history = case_when(
credit_history == ‘A30’ ~ ‘no credits taken/ all credits paid back duly’,
credit_history ==’A31′ ~ ‘all credits at this bank paid back duly’,
credit_history==’A32′ ~ ‘existing credits paid back duly till now’,
credit_history==’A33′ ~ ‘delay in paying off in the past’,
credit_history==’A34’~ ‘critical account/other credits existing (not at this bank)’
)
#etc
)
Meer info: https://www.computerworld.com/video/87435/r-tip-learn-dplyr-s-case-when-function
He bedankt Paul! Dat is inderdaad beter leesbaar dan ifelse(), thanks voor de tip:)
[…] Kunnen we voorspellingen van algoritmes vertrouwen? Wel als een voorspelling onderbouwd kan worden: https://arietwigt.nl/2019/04/09/voorspellingsmodellen-volledig-vertrouwen/ […]