
Microsoft Azure Batch en R – Doorlooptijden terugbrengen van Dagen naar Uren
Veel input data, lange wachttijden
De definitie van Big Data is in de loop der tijd bij steeds meer bedrijven doorgedrongen. Veel mensen kunnen op dit moment wel een definitie van Big Data bedenken. Een voorbeeld van een eenvoudige definitie is: ”Data dat te omvangrijk is om op een enkele machine op te slaan of te verwerken.”, en dan zit ik nog in de redelijk onschuldige hoek. Het komt er in ieder geval op neer dat je een dataset uit deze categorie niet moeiteloos op je eigen machine kunt bewerken. In sommige gevallen lukt het verwerken nog wel, maar zijn er stukken in dit proces die extreem lang duren. Soms wel dagen. En dan heb ik het niet eens over de verwerking van het resultaat.
Big data in de cloud: Microsoft Azure
Om met deze hoeveelheden aan data te werken en om binnen een korte tijd resultaat te halen, is een architectuur nodig met de juiste tools. Tools die je niet in huis hoeft te hebben, maar die je eenvoudig binnen een paar klikken beschikbaar hebt in de cloud. Bijvoorbeeld het cloud platform Microsoft Azure. Als eindresultaat kun je calculatietijden terugbrengen van dagen naar uren.
De architectuur die ik in dit artikel beschrijf, is een Microsoft Azure Batch Architectuur. Deze bestaat uit 3 hoofdcomponenten en services van Microsoft Azure:
· Microsoft Azure Batch;
· Microsoft Azure Blob Storage;
· Microsoft Azure SQL Datawarehouse (met PolyBase).
In dit artikel leg ik op architectuur-niveau uit hoe je met een grote dataset door middel van deze tools alsnog binnen een redelijke tijd resultaat kunt verzamelen.
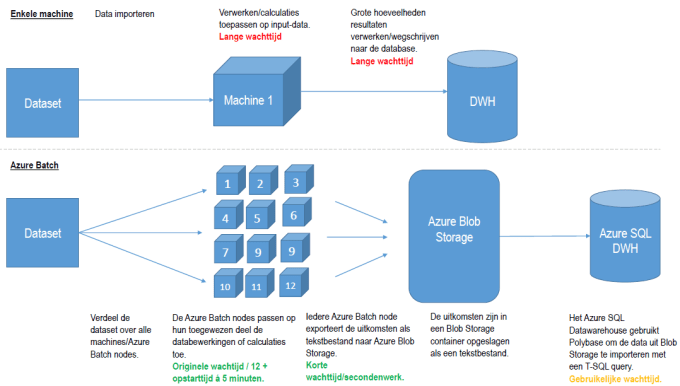
Verdeel en heers
Hoe verwerk je data dat niet op een enkele machine past? ……. Meerdere machines gebruiken. Dat is exact de dienst die Azure Batch levert: direct een x aantal kale machines (nodes) aanzetten om een data te verwerken en het resultaat te exporteren. Een verzameling van deze machines wordt een pool genoemd, de machines in deze pool worden nodes genoemd. De nodes draaien parallel en gaan tegelijkertijd aan de slag met de dataverwerking. Samen met de ongeveer 5 minuten aan opstarttijd kun je grofweg zeggen dat de berekening met een factor sneller wordt bij iedere extra node. Dit hangt natuurlijk ook af van de manier waarop de databewerking is ingericht.
Hoe ziet de node er uit?
Een node is een kale virtuele machine met Windows. Hier kun je dus alles op installeren en laten uitvoeren. De configuratie van een node wordt uitgevoerd via een Command Line script, bijvoorbeeld om software op de node te installeren.
Een voorbeeld: Er moeten relatief zware calculaties worden uitgevoerd met de statistische programmeertaal R. De volgende bestanden worden naar iedere node gestuurd:
· De R installer: Om R op de node te installeren;
· De gehele of deel van de dataset;
· Het R script die de databewerkingen en het R-script bevat;
· De R packages;
· Een Command Line script die aangeeft wat de taken zijn van de node.
Om hier dieper op in te gaan zal ik later een demo publiceren zodat je een beter beeld krijgt hoe het batch proces echt in zijn werk gaat. Ook staat Sogeti op de aanstaande Big Data Expo in de Jaarbeurs Utrecht, o.a. deze technologie wordt hier gepresenteerd.
Hoe ziet het proces er uit?
Natuurlijk wil je inzicht hebben in het proces zodra deze is gestart. Hiervoor kun je het Batch Explorer programma gebruiken, welke op dit moment nog open source is.
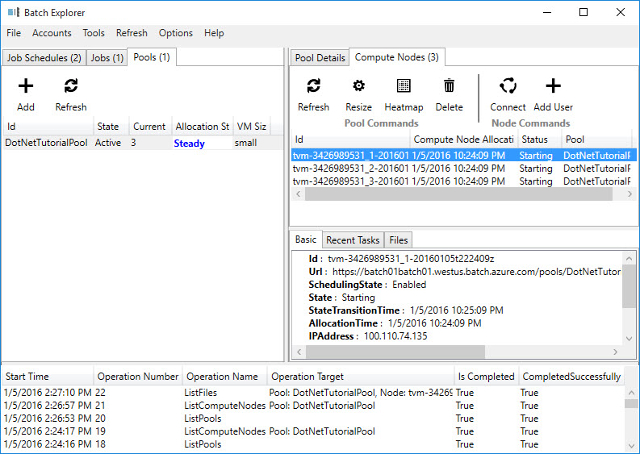
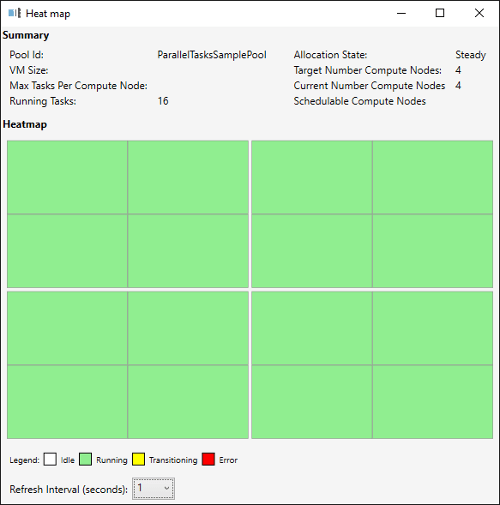
Hiermee kun je de aangemaakte pool zien en door middel van de heatmap zien wat in welke fase de nodes zich bevinden. Ook is het mogelijk om via een Remote Desktop Connection in te loggen op een node zodat je precies kunt zien hoe de node er uit ziet.
Benodigdheden
Om Azure Batch te gebruiken heb naast je eigen data en scripts de volgende resources nodig:
- Azure Batch account;
- Azure Batch Explorer;
- Azure Blob Storage container;
- Azure SQL Datawarehouse;
- Een .NET of Python script om het Azure Batch proces te organiseren.
Deze services zijn zeer eenvoudig te regelen als je een Microsoft Azure account hebt.
Output data verzamelen en opslaan
Als de databewerkingen resulteren in grote hoeveelheden aan output data, moet deze natuurlijk ook op een efficiënte manier worden opgeslagen. In het geval van grotere hoeveelheden data is direct wegschrijven naar de database niet de beste optie. Alle namelijk nodes schrijven tegelijkertijd grote hoeveelheden data naar de database waardoor er overhead ontstaat die op zijn plaats weer tot een extreem lange wachttijd kan leiden.
Zoals eerder aangegeven, kun je er voor kiezen door iedere node data te laten exporteren als tekstbestand. Zo goed als iedere programmeertaal of software waarmee je data bewerkt, is dit mogelijk. Door data eerst als tekstbestand te exporteren en dan in te laden in de database, knip je het proces in twee delen wat aan het eind van de rit veel efficiënter en sneller is.
Tekstbestand exporteren naar Azure Blob Storage.
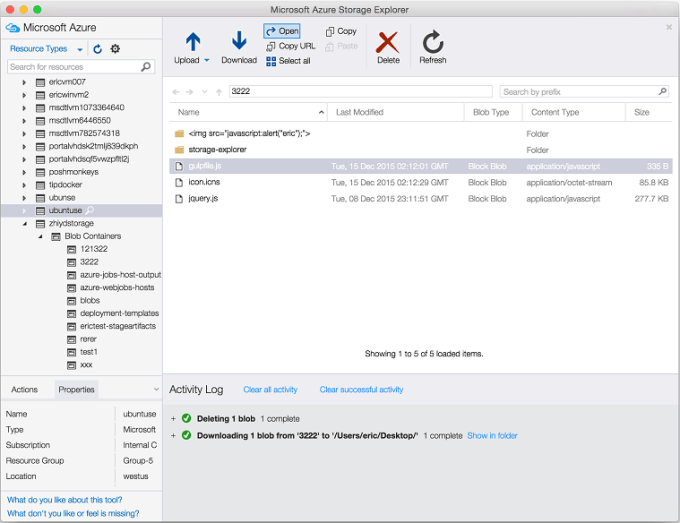
Ieder resultaat van een Azure Batch node wordt geëxporteerd naar een Azure Blob Storage container. Aan het einde van de rit zit de gehele output data in de container in de vorm van aparte tekstbestandjes. Met met Azure Storage Explorer kun je eenvoudig een kijkje nemen of alle data aanwezig is en hoe de data er uit ziet.
Data inladen in het Azure SQL Datawarehouse met Polybase
Het Azure SQL Datawarehouse (ASQLDWH) kun je gebruiken om een database aan te maken die aan het einde van het proces de output data wordt opgeslagen. Door deMicrosoft Polybase functionaliteit die je hebt in het ASQLDWH kun je eenvoudig met een T-SQL script de data uit Blob Storage importeren. Onder de motorkap worden er namelijk MapReduce jobs geschreven en uitgevoerd op de tekstbestanden in de Blob Storage container. Hoe lang dit duurt, is afhankelijk van de hoeveelheid aan data. Als benchmark; in mijn huidige project doet Polybase er 1,5 uur over om 1,5 miljard rijen uit Blob Storage naar de database te importeren. Samen met het exporteren van de tekstbestanden uit Azure Batch, dat slechts een kwestie van secondenwerk is, is dit proces significant sneller dan direct wegschrijven naar de database.
Slot
Het is mogelijk om met een eenvoudige architectuur, weinig resources en een eenvoudige configuratie in de cloud baanbrekende resultaten te bereiken op het gebied van doorlooptijden van databewerkingen. Op dit moment heeft Azure Batch nog een vrij open source karakter en is de support nog niet optimaal. Daarentegen heb je de volledige vrijheid om de oplossing naar jouw eigen wensen te bouwen. Daarbij is de documentatie van Microsoft op dit gebied goed, vooral op het gebied van handleidingen en stukken voorbeeldcode.
In dit artikel ben ik vooral op architectuur-niveau ingegaan op dit onderwerp. Echter ben ik in de praktijk juist bezig geweest op het technisch niveau van deze oplossing. In dit geval het schrijven van de code, query’s, configuratie en het draaien van de Azure Batch runs. Mocht je dus vragen hebben hierover, kun je gerust contact met mij opnemen. Alvast een fijne zondag toegewenst.

Plaats een reactie