
R en SQL Database deel 2 – Voorspellingsmodel maken voor fraude detectie
Inleiding
In het vorige deel van deze tweeluik heb ik laten zien hoe je in R verbinding maakt met een bestaande database. Hierdoor kun je de kracht van R gebruiken om data uitgebreid te analyseren en te visualiseren. In deze post gaan we een stukje verder, namelijk een voorspellingsmodel ontwikkelen en gebruiken. De case is fraudedetectie: Er wordt een voorspellingsmodel gemaakt om de kans op fraude bij studenten en hun studiefinancieringen weer te geven. Dit voorspellingsmodel wordt getraind op basis van historische gegevens van studenten waarbij het bekend is of er sprake was van fraude of niet, een zogenaamde ‘train-dataset’. Ik gebruik geen statistische, econometrie of wiskundige taal hier maar beoordeel aan het eind van het proces het voorspellingsmodel door gewoon te checken of de hoge kansen op fraude (teruggegeven door het model) ook achter de daadwerkelijke fraudegevallen staan. We gaan in de volgende stappen te werk:
- Data bekijken in de database;
- R package intstalleren en bekijken;
- Koppeling maken R en database;
- De voorspelling uitvoeren en beoordelen.
De ingrediënten voor dit recept zijn:
- R/RStudio;
- Een test studenten dataset;
- Kernlab package;
- RODBC package;
- Database;
- (eventueel) Microsoft SQL Server Management Studio (SSMS).
De dataset met studentengegevens maken/bekijken
Je kunt gewoon zelf een dataset verzinnen, dat heb ik zelf ook gedaan. Alle namen zijn door een random name generator gemaakt en alle namen van scholen en afstanden heb ik random ingevuld. Per rij heb ik ten slotte aangegeven of er sprake was van fraude of niet (0 is nee en 1 is ja). De resultaten heb ik minder willekeurig verzonnen omdat je zelf wilt bepalen hoe de situaties van fraude en geen fraude zijn verdeeld. Je kunt eenvoudig zelf zo’n dataset maken. Als je daar geen tijd voor heb kun je de dataset die ik gebruikt heb hier downloaden (je kunt deze dataset dan als csv-bestand importeren in R).
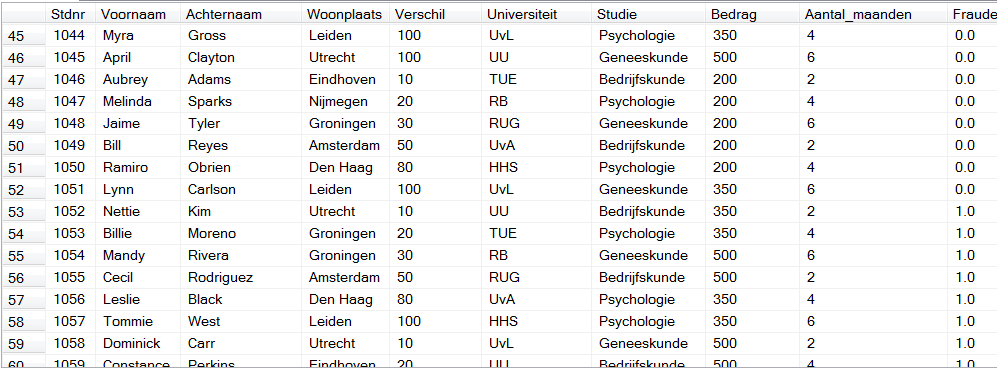
Meta-gegevens van de kolommen in de dataset:
| Kolom | Betekenis | Formaat |
| Stdnr | Studentnummer van de student | Numeric |
| Voornaam | Voornaam van de student | Nchar |
| Achternaam | Achternaam van de student | Nchar |
| Woonplaats | Woonplaats van de student | Nchar |
| Verschil | Verschil tussen woonplaats en school student | Numeric |
| Universiteit | Naam van de school/universiteit van de student | Nchar |
| Studie | Studie van de student | Nchar |
| Bedrag | Bedrag studiefinanciering van de student | Numeric |
| Aantal_maanden | Aantal maanden dat de student de studiefinanciering heeft | Numeric |
| Fraude | Geeft aan of er sprake was van fraude of niet | Numeric |
Het voorspellingsmodel om fraude te detecteren
Voor de voorspelling wordt er gebruik gemaakt van een kernal support vector machine. Dit model helpt met classificeren. In het paper van Karatzoglou et al. (2004) wordt gedemonstreerd hoe er een model getraind kan worden om aan te voorspellen welke eigenschappen bij welke bloem horen door kansen weer te geven op basis van de eigenschappen van de bloem. Hier volgt een korte demonstratie van hoe dit werkt.

Hierboven zie je een screenshot van een gedeelte (de eerste 12 rijen) van de iris dataset. Deze geeft aan dat het soort een ‘setosa’ is en deze bepaalde eigenschappen heeft. De iris dataset heeft 3 verschillende soorten (species) die elke aparte eigenschappen hebben. Er wordt een model getraind die kijkt welke eigenschappen bij welke species horen en daarbij op basis van kansen klassifiseert op waarschijnlijkheid om welk soort het gaat.
Het model wordt getraind:
irismodel<-ksvm(Species~.,data=iris,
+ type=”C-bsvc”,kernel=”rbfdot”,kpar=list(sigma=0.1),C=10,prob.model=TRUE)
Voor willekeurige rijen in de iris dataset worden nu voorspellingen teruggegeven waarbij voor ieder soort (Species) de waarschijnlijkheid wordt weergegeven dat het dat soort bloem is:

Je kunt zien dat er per rij de kans ziet om welke bloem het gaat, rijen 3, 10, 56, 68, 107 en 120 zijn gekozen. Als we dat controleren zie je dat het model dit uitstekend voorspelt omdat de hoge kansen worden gegeven bij de soorten waar het daadwerkelijk om gaat. Dit gaan we ook met onze studenten dataset doen: het resultaat is in dat geval in plaats van het type bloem, de situatie of het fraude was ja of nee (0 of 1). De eigenschappen van de bloemen zijn in de studentencase dan de eigenschappen van de student en de relatie (ook qua studiefinanciering) met de onderwijsinstelling. Lets do it!
Data importeren uit de database.
In het vorige deel heb je kunnen zien hoe een datasource voor verbinding met de database gemaakt kan worden. In R importeren we nu de Studenten-tabel (die we voor het gemak in de gebruikelijke AdventureWorks database hebben gestopt.

Uiteindelijk is de tabel geïmporteerd in R.

Nu de tabel met studentengegevens is geïmporteerd in R, trainen we het voorspellingsmodel. Zie het stukje “ ksvm(Fraude~ ”, welk aangeeft dat de variabele Fraude wordt voorspelt op basis van de al voorgaande variabelen.

Nu het voorspellingsmodel is gemaakt, kunnen we voorspellingen gaan doen. We voorspellen gelijk in 1 keer de hele dataset zodat we uiteindelijk een nieuwe dataset krijgen met elke student en diens kans op fraude als laatste kolom.
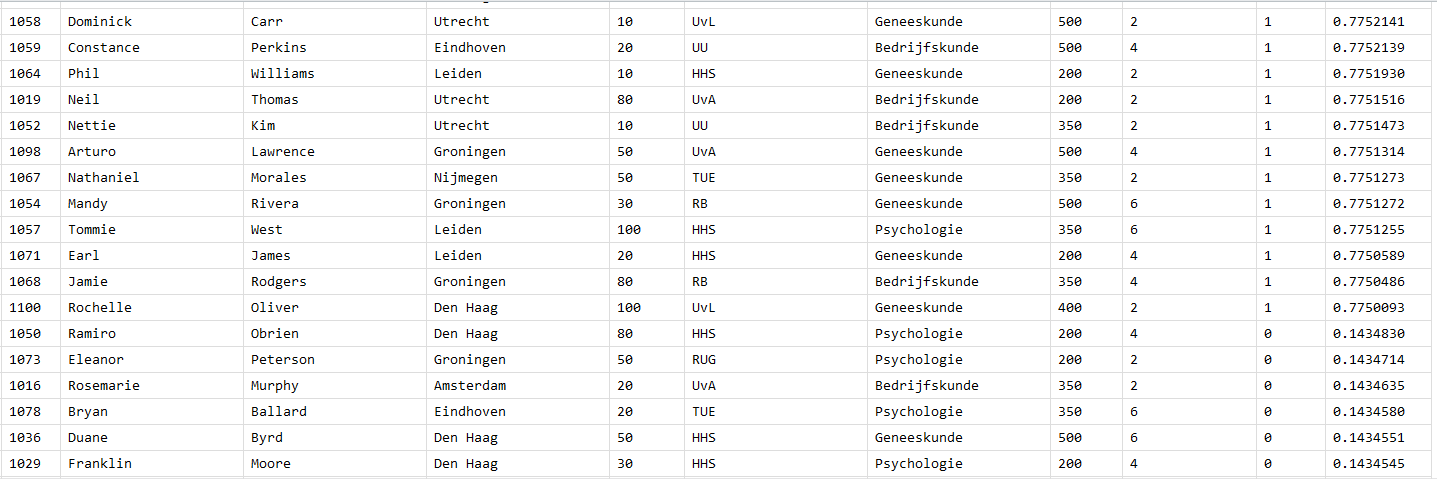
Dit resulteert in de in de onderstaande tabel: Voor elke situatie zie je de fraude kans, de voorlaatste kolom geeft aan of er daadwerkelijk sprake is geweest van fraude of niet. Het voorspellingsmodel voorspelt goed als de hoge kansen op fraude naast de 1tjes staan, dan geeft het model namelijk een hoge kans op fraude voor situaties waar er daadwerkelijk sprake is geweest van fraude. Zoals je in de onderstaande tabel ziet is daar sprake van en is het dus een goed voorspellingsmodel.
Conclusie: Fraude detectie als hulpmiddel voor efficientie
Je ziet dat je op een vrij eenvoudige manier met je huidige omgeving qua data al aan voorspellingsmodellen kunt doen. Er zijn veel voorspellingsmodellen beschikbaar, een (logistische regressie zou hier ook prima zijn werk doen). Als resultaat heb je door deze stappen met het voorspellingsmodel een prioritering van welke situaties de meeste aandacht verdienen. Je kunt je tijd op deze manier optimaal inzetten door situaties grondiger te onderzoeken waar de kans op fraude het hoogst is, het model dient hiervoor als uitstekend hulpmiddel door de kansen die het geeft. Het is belangrijk om dit ook als hulpmiddel te blijven zien en altijd ons gezonde verstand te blijven gebruiken. Een model is een model en doet alleen wat je vraagt hem te doen en geeft terug op basis van wat hij aangeleverd krijgt. Het model heeft totaal geen verstand van fraude.

Plaats een reactie